Chunk Text
The Chunk Text component divides large text content into smaller, manageable chunks based on token count. This component is essential for processing large documents in Retrieval Augmented Generation (RAG) systems by breaking them down into pieces that can be effectively embedded and retrieved from vector databases. By specifying chunk size and overlap parameters, users can optimize how their text is divided while maintaining context continuity between segments.
Overview
The Chunk Text component prevents context loss through intelligent overlap mechanisms while ensuring chunks fit within downstream processing limits. The text input typically comes from extracted document content via session variables, direct user input, or hardcoded values depending on the pipeline flow. Chunk size should be strategically chosen between 300-500 tokens for optimal balance between semantic coherence and processing efficiency - smaller chunks provide precise retrieval but may lose context, while larger chunks maintain context but may exceed model limits. The overlap size creates shared token boundaries between adjacent chunks, typically 20-50 tokens proportional to chunk size, preventing meaningful phrases or sentences from being split awkwardly and ensuring semantic continuity for better retrieval accuracy in RAG applications. When overlap is not needed for independent chunk processing, set overlap_size to 0. The component returns a simple list of text strings rather than complex objects, making it easy for downstream components to iterate through chunks in loops or process them individually.
Primary use cases include RAG pipeline preparation where chunks are embedded and stored in vector databases, large document processing that exceeds LLM context limits requiring segmentation, and text analysis workflows needing manageable content portions. The component automatically handles edge cases like text smaller than chunk size by returning single chunks without unnecessary splitting, and uses precise token counting rather than character counting for accurate LLM compatibility.
How to use:

Key Terms
Term |
Definition |
|---|---|
Chunk |
A segment of text extracted from a larger document, sized appropriately for processing by language models or embedding systems. |
Token |
The basic unit of text processing in language models roughly corresponds to parts of words or punctuation. |
Overlap |
The number of tokens shared between adjacent chunks to maintain context continuity across chunk boundaries. |
RAG |
Retrieval Augmented Generation - a technique that enhances LLM responses by retrieving relevant information from external knowledge sources. |
When to Use
Use when processing large documents or text that exceeds the context window of your language model.
Ideal for preparing text for embedding into vector databases.
Helpful when implementing RAG workflows that require manageable pieces of text for efficient retrieval.
Use when you need to maintain semantic coherence across segments of a large document.
Component Configuration
Required Inputs
Input |
Description |
Data Type |
Example |
|---|---|---|---|
Text |
The text content is to be divided into chunks. Users can type or paste text directly into this field. This text can come from documents, articles, or any long-form content that needs to be broken into smaller segments |
String |
|
Chunk Size |
The maximum number of tokens per chunk determines the size of each text segment. |
Integer |
|
Overlap Size |
The number of tokens to overlap between consecutive chunks. This helps maintain context across chunk boundaries. If not specified, a default value of 100 tokens is used |
Integer |
|
How It Works
The component first validates all input parameters to ensure they meet the requirements.
The text is then divided into chunks based on the specified chunk size.
Each chunk overlaps with the next by the specified overlap size to maintain context continuity.
If the text is smaller than the chunk size, the entire text is returned as a single chunk.
The component outputs an array of text chunks, each representing a portion of the original text.
Example Use Case
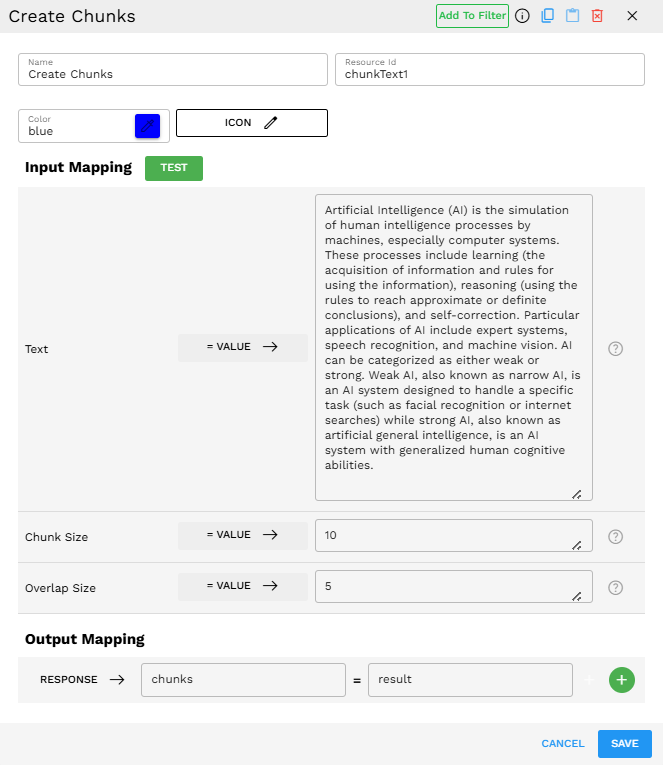
Configuration
Text: "Artificial Intelligence (AI) is the simulation of human intelligence processes by machines, especially computer systems. These processes include learning (the acquisition of information and rules for using the information), reasoning (using the rules to reach approximate or definite conclusions), and self-correction. Particular applications of AI include expert systems, speech recognition, and machine vision. AI can be categorized as either weak or strong. Weak AI, also known as narrow AI, is an AI system designed to handle a specific task (such as facial recognition or internet searches) while strong AI, also known as artificial general intelligence, is an AI system with generalized human cognitive abilities."
Chunk Size: 10
Overlap Size: 5
Process
The component processes the provided text
It creates chunks with a size of 10 tokens each
Each chunk overlaps with the next by 5 tokens
The output is an array of text chunks
Output
[
"Artificial Intelligence (AI) is the simulation of",
") is the simulation of human intelligence processes by machines",
" human intelligence processes by machines, especially computer systems.",
", especially computer systems. These processes include learning (",
" These processes include learning (the acquisition of information and",
"the acquisition of information and rules for using the information",
" rules for using the information), reasoning (using the",
"), reasoning (using the rules to reach approximate or",
" rules to reach approximate or definite conclusions), and self",
" definite conclusions), and self-correction. Particular",
"-correction. Particular applications of AI include expert",
" applications of AI include expert systems, speech recognition,",
" systems, speech recognition, and machine vision. AI",
" and machine vision. AI can be categorized as either",
" can be categorized as either weak or strong. Weak",
" weak or strong. Weak AI, also known as",
" AI, also known as narrow AI, is an",
" narrow AI, is an AI system designed to handle",
" AI system designed to handle a specific task (such",
" a specific task (such as facial recognition or internet",
" as facial recognition or internet searches) while strong AI",
" searches) while strong AI, also known as artificial",
", also known as artificial general intelligence, is an",
" general intelligence, is an AI system with generalized human",
" AI system with generalized human cognitive abilities."
]
Best Practices
Choose an appropriate chunk size based on your embedding model's capabilities and the downstream LLM context window.
Set a reasonable overlap size to maintain context continuity. A good rule of thumb is 10-20% of the chunk size.
Troubleshooting
Issue |
Possible Cause |
Solution |
|---|---|---|
"Chunk size is required" error |
The chunk_size parameter is missing or empty |
Ensure you provide a valid integer value for the chunk size. |
"Chunk size must be positive" error |
A zero or negative value was provided for chunk size |
Provide a positive integer value for chunk size. |
"Overlap size must be less than chunk size" error |
The overlap size is equal to or greater than the chunk size |
Reduce the overlap size to less than the chunk size. |
Limitations and Considerations
Context limitations - Even with overlap, some context might be lost between chunks, especially for complex documents with long-range dependencies.
No natural language understanding - The chunking algorithm does not understand the content semantically, so it does not automatically preserve paragraphs, sections, or other logical structures.